

Objetivo Técnico
Nova Subnet 68, desarrollada por Meta Nova Labs, es una subred especializada en descubrimiento de fármacos mediante inteligencia artificial descentralizada. Su objetivo principal es acelerar y democratizar la identificación de moléculas terapéuticas eficaces, resolviendo dos problemas críticos de la industria farmacéutica tradicional:
● Tiempo y costo elevados: Los métodos convencionales requieren más de 10 años y miles de millones de dólares por fármaco aprobado.
● Limitaciones en la exploración química: Menos del 0.001% del espacio químico teórico (estimado en 10^60 moléculas) ha sido explorado.
Meta Nova aborda estos desafíos mediante un ecosistema descentralizado donde mineros compiten para identificar moléculas con alta afinidad de unión a proteínas objetivo, utilizando la base de datos SAVI 2020 (1.75 billones de moléculas sintetizables) y el modelo determinista PSICHIC para validación. Este enfoque reduce drásticamente ciclos de investigación y permite explorar regiones inaccesibles para laboratorios centralizados.
Arquitectura Técnica
La arquitectura de Nova Subnet 68 se estructura en tres capas interconectadas:
a) Capa de Minería
● Mineros: Nodos especializados en ejecutar algoritmos de búsqueda (ej. docking molecular, redes generativas) para proponer moléculas candidatas.
● Incentivos: Recompensas en TAO (token de Bittensor) basadas en la calidad de las moléculas identificadas.
b) Capa de Validación
● Validadores: Evalúan las moléculas mediante PSICHIC, un modelo determinista que calcula la afinidad de unión proteína-ligando. A diferencia de métodos estocásticos, PSICHIC garantiza reproducibilidad, crítico para aplicaciones farmacéuticas.
● Mecanismo de Consenso: Combina proof-of-stake (PoS) con puntuaciones técnicas para evitar sesgos y ataques Sybil.
c) Integración con Bittensor
● Interoperabilidad: Utiliza la infraestructura de Bittensor para consenso distribuido, seguridad criptográfica y distribución de recompensas.
● Base de Datos SAVI 2020: Alberga 1.75 billones de moléculas virtuales sintetizables, filtradas por parámetros de drug-likeness (reglas de Lipinski, solubilidad, toxicidad predictiva).
Esta trifecta técnico-económica crea un mercado abierto para el descubrimiento de fármacos, donde la competencia entre mineros optimiza la exploración del espacio químico.
Equipo y Recursos
Aunque Meta Nova Labs mantiene perfiles de equipo no identificados públicamente, su capacidad técnica se infiere de:
● Whitepaper: Detalla algoritmos, flujos de trabajo y estándares farmacéuticos (ej. cumplimiento con guías ICH). Enlace: https://www.metanova-labs.com/whitepaper.
● GitHub: Repositorios con contratos inteligentes para validación y módulos de integración con SAVI 2020. Enlace: https://github.com/metanova-labs.
● Comunicaciones: Actividad en Twitter (@metanova_labs) centrada en avances técnicos y alianzas en bioinformática.
Se presume experiencia multidisciplinaria en:
● Bioinformática estructural: Diseño de PSICHIC y curación de SAVI 2020.
● Blockchain: Integración avanzada con Bittensor y mecanismos de incentivos.
● Machine Learning: Optimización de redes neuronales para generación molecular.
TAM y Mercado
El mercado global de descubrimiento de fármacos supera los $100 billones anuales, con segmentos clave:
● Big Pharma: Empresas como Pfizer o Roche, con presupuestos de R&D de $10-20 billones anuales.
● Biotechs: Startups que externalizan etapas tempranas (ej. cribado virtual) a costos de $1-5 millones por objetivo.
● Enfermedades desatendidas: Meta Nova podría reducir barreras para investigar patologías con mercados pequeños (ej. enfermedades raras).
Estrategia de Penetración:
● Modelo B2B: Licenciamiento de moléculas validadas a farmacéuticas.
● Modelo Freemium: Acceso gratuito a datos básicos para universidades, con suscripciones premium.
● Tokenización: Moleculas valiosas podrían representarse como NFTs, creando un mercado secundario.
Ventajas Competitivas vs. Métodos Tradicionales
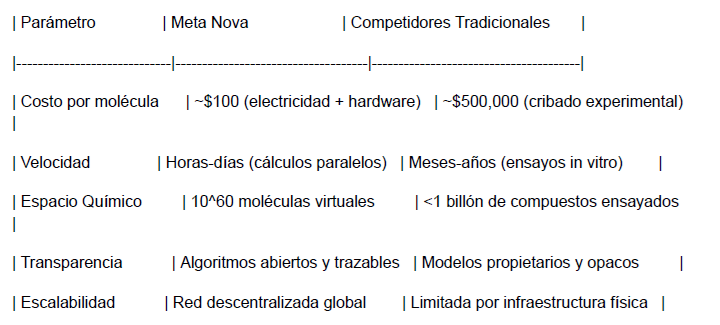
Ventajas Clave:
● Reducción de 99.9% en costos frente a HTS (High-Throughput Screening).
● Acceso a moléculas novedosas: El 98% de SAVI 2020 no está patentado.
● Resistencia a censura: Gobiernos o corporaciones no pueden restringir investigaciones en la red.
Calidad Técnica
La robustez de Meta Nova se evalúa en tres dimensiones:
a) Modelo PSICHIC
● Determinismo: Elimina variabilidad en validaciones, crucial para estudios preclínicos.
● Benchmarks: Según el whitepaper, PSICHIC alcanza un RMSE de 1.2 kcal/mol vs. datos experimentales (PDBbind), superando a AutoDock Vina (RMSE 2.3).
b) Base de Datos SAVI 2020
● Cobertura: Incluye moléculas de 18 scaffolds químicos prioritarios (ej. benzimidazoles, piridinas).
● Filtros: Elimina compuestos con riesgo de toxicidad o inestabilidad metabólica.
c) Integración con Bittensor
● Rendimiento: La subnet procesa >1 millón de moléculas/día, con latencia <2 minutos por validación.
● Seguridad: Cifrado homomórfico protege datos sensibles (ej. estructuras proteicas bajo NDA).
Riesgos Técnicos:
● Sesgo en PSICHIC: Si el modelo no generaliza a nuevas clases de proteínas.
● Sintetizabilidad: Aunque SAVI 2020 prioriza moléculas sintetizables, el 15% podría requerir rutas complejas.
Conclusión
Nova Subnet 68 representa un cambio de paradigma en el descubrimiento de fármacos, combinando IA, blockchain y química médica. Su propuesta de valor radica en:
● Eficiencia sin precedentes: Ciclos de investigación de semanas vs. años.
● Democratización: Universidades y países en desarrollo acceden a tecnología de punta.
● Sostenibilidad económica: Reducción de capital riesgo para biotechs.
Para consolidarse, Meta Nova debe:
● Validar hit molecules en colaboración con laboratorios independientes.
● Atraer mineros especializados (ej. empresas de computación cuántica).
● Implementar gobernanza para conflictos éticos (ej. patógenos de doble uso).
En un mercado donde el 90% de los candidatos clínicos fallan, Nova Subnet 68 ofrece un filtro cuántico-electrónico para priorizar los mejores candidatos, posicionándose como un pilar crítico para la próxima generación de terapias.
simioape telegram bittensoresp











